
{kind=link}
Parallel computers can be found today in numerous multi-core processor systems from smartphones to tablets and PCs to industrial control systems and computer clusters in the data center. The use of this computing power poses major challenges to software development – in addition, parallel programming paradigms have to be considered.
Unlike traditional applications with the sequential program flow, Parallel Computing runs several subtasks simultaneously. This is also called concurrency or parallelism. The advantages are obvious: Parallel processing allows multi-core systems to be used efficiently and complex problems to be solved in a reasonable amount of time. However, this also goes hand in hand with significantly higher complexity and poorer traceability of the program code as well as a higher error rate.
This article discusses concepts, techniques, and challenges of concurrent programming with Java threads and aims to answer the following questions:
-
How can you achieve high utilization across many CPU cores?
-
How to deal with race conditions and data races?
-
What pitfalls lurk when using synchronization techniques?
In parallel processing, developers often distinguish between task parallelism and data parallelism. Task parallelism handles a number of different tasks in parallel and independently on the same or different data. In principle, a similar process, as when several cooks prepare a burger and parallel doing the individual steps such as the preparation of lettuce, tomatoes, bread rolls and meatballs (see Fig. 1).

In data parallelism, the same task is performed in parallel on different areas of a data set. As if several cooks were processing a burger order (a record) and making the burgers at the same time.
Parallel execution accelerates applications – but within limits
How much an application can be accelerated by parallel execution depends, according to Amdahl’s law, on the sequential (ie non-parallelizable) portion of an application. For example, several cooks prepare the individual ingredients of the burger, but only one cook adds them together sequentially(see Fig. 2).

The total preparation time thus depends on the five minutes that a single chef needs to put the ingredients together. Even if many cooks cook and speed up the preparation of the ingredients (parallel portion), the total time never falls below five minutes.
A high parallel efficiency can be achieved if the problem is well parallelized and has the lowest possible sequential share. Good parallelism also means that the individual subtasks can be completed in the same execution time. Otherwise, the problem shown in Figure 3 occurs.
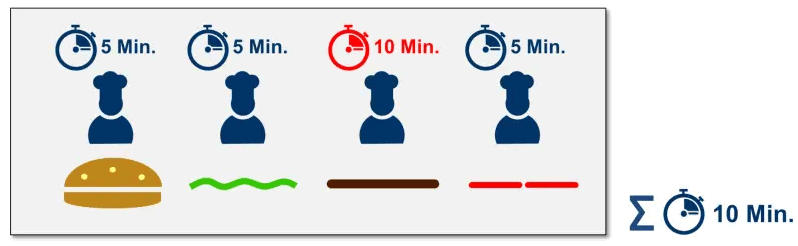
The cook who prepares the meatballs takes much more time than the other three cooks. This not only increases the processing time of the parallel portion but also causes the other three cooks to wait five minutes and have nothing to do until the last cook is done.
In order to efficiently utilize a multi-core system, a problem with high parallelization is thus necessary. In particular, problems that apply the same algorithm to different areas of a data set (data parallelism) are well suited for this. Areas of application such as the simulation of physical processes or the training of neural networks are particularly predestined. On the other hand, applications such as office applications or web servers often cannot be parallelized.