
{kind=link}
OpenAI developers have created neural network agents who have independently learned various hide and seek strategies. For example, in the beginning, the hiding agents learned to block the passageways in large blocks, but after a while, the searching agents learned to use ladder blocks to overcome the walls, after which the first ones began to block the stairs, the authors say in the blog, as well as in the article.
Usually, when teaching neural network algorithms, a teaching method with a teacher is used. For example, in order to train the algorithm to recognize cats in photographs, it is easiest to provide him with a lot of photographs on which cats and other objects will be marked. Thus, the trained algorithm explicitly receives examples of work. However, there is a completely different approach called reinforcement learning. It implies that the algorithm receives only an abstract award or a fine from the learning environment.
OpenAI researchers have long used this approach to teach algorithms complex behavior. For example, among recent works, one can single out a robot arm, which has learned dozens of times in a row to turn a cube with your fingers into the desired position. In a new work, the researchers decided to use this method for teaching algorithms to collective behavior using the example of a game of hide and seek.
The learning environment is a flat virtual training ground on which the agents themselves are located, as well as fixed and moving obstacles. As a rule, agents were trained in the format of teams two by two or three by three, and the award or penalty depended on the behavior of all the partners in each team. The task of the agent-catchers is to keep the hiding agents in direct line of sight, and the hiding agents, on the contrary, tend not to catch the eye of the catchers. Before the start of each round, the sheltering team is given little time to prepare.
The rules for interacting with the environment are the same for both teams. Agents can move themselves, move moving objects, and also block them, making them motionless, and only the same team can unlock them after that, but not rivals. Agents can also look at the environment using a virtual lidar and camera.
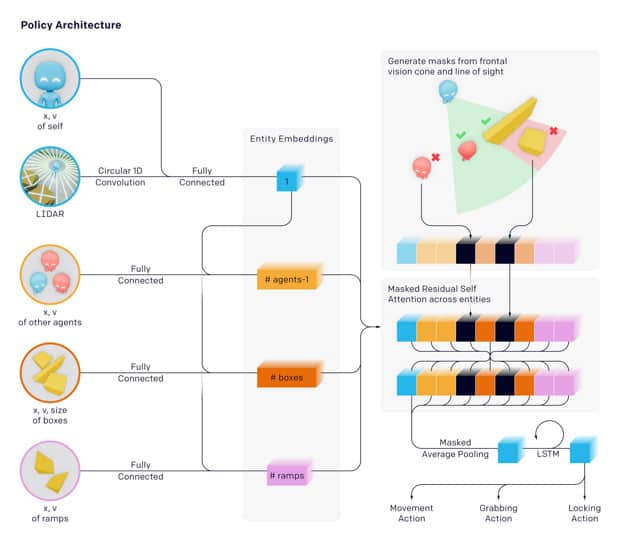
The developers tested three types of moving blocks: cubes, stairs (half a cube) and long moving walls. In addition, fixed obstacles also changed: at first the training ground was a large room and a small one, connected by two aisles, and then the agents competed in a more open environment. Each round lasts 240 conditional steps, with the first 96 of them hiding the team hiding, and the team of catchers can not move, and both teams do not receive any reward or fine.
Researchers trained copies of algorithms in parallel, periodically updating their behavior. Initially, the agents moved randomly, then the catchers learned to chase the hiding agents, and after about 25 million rounds, a turning point came when the hiding agents learned to change the environment by moving moving blocks and forming a room out of them. After about 75 million more rounds, the catchers worked out a response strategy and learned how to put the stairs against the walls to jump over them and get into the room blocked by the team that was hiding. After another 10 million rounds, the sheltering team found the answer to this – they learned to block all the blocks they did not need so that they would not go to the opponents.
Researchers noted that hiding agents learned an even more impressive skill. In the case when the blocks were located far away, to achieve a common goal, they began to pull the block closer to the partner along the road, after which they were taken for the main goal. The authors note that in some cases, agents surprised them using behavioral strategies that the developers were not aware of. For example, after blocking the stairs by a sheltering team, the catchers learned to move blocks to them, climb the blocked stairs, and then move astride the block to the right place.