{kind=link}
Some research in the field of robotics is not aimed at creating the robots themselves, but at researching the aspects of human perception of robots. For example, there is the phenomenon of the “sinister valley”, which consists in the fact that increasing the realism of the robot makes it more attractive only to a certain threshold, after which realism causes negative emotions. There are many other aspects that influence trust between people and machines, including clarity of the current actions and intentions of the machine.
For example, developers of unmanned vehicles, such as Ford and Mercedes, are experimenting with various light signals that allow pedestrians to understand the plans of unmanned vehicles and be less afraid of them on the streets.
Engineers led by Song-Chun Zhu of the University of California, Los Angeles conducted a study to understand how robots can explain their actions to humans. The authors conducted a study using an example of a simple and common task: opening a can, with a protective mechanism. As a hardware platform, they took the Baxter robot, popular among robot researchers, with two arms, a torso and a monitor. In addition, they used a glove with sensors, which allows you to record both the positions of all parts of the brush and the forces applied to the can and lid during sessions of unscrewing the covers.
In the experiment, the robot watched people through these gloves, and then built a high-level schematic representation of this task (for example, “grab a can, press the lid, turn the lid”) and created using a neural network encoder an analogue of human actions taking into account differences in the structure of the human hands and robot manipulator. The method of teaching through a demonstration is based on the previous work of the authors, and in addition, earlier other researchers have already created similar systems, even more impressive, for example, a robot that can repeat an action after a person according to one example.
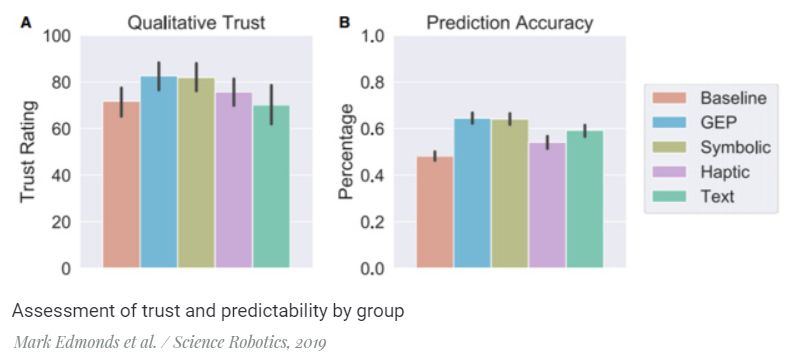
The main innovation of the work is the study and comparison of methods for explaining the actions of the robot. The authors compared four types of such explanations: through a video recording of a robot unscrewing the lid, through a sequence of basic actions, through a schematic animation with visualization of effort, and also through a text description in simple language.

The study involved 150 people who were randomly assigned to one of five groups. The video was shown to the participants of each group, and four groups of five besides it also received explanations using one or two other methods from the list:

After observing the actions of the robot and the explanations of the participants, they were asked to evaluate the confidence in the actions of the robot, by which in this study the authors understood the rational component of trust rather than the emotional one. Then they were shown another similar action and before that, they were asked to predict the plans of the robot.
It turned out that the highest ratings for both parameters (trust and predictability) were given by the members of the group, which showed an explanation in the form of a sequence of basic actions and schematic animation. Participants in the group that received only the sequence of basic actions gave almost the same, albeit slightly lower grade.